 |
libftsh
A Fast Transform for Spherical Harmonics
|
|
libftsh
A Fast Transform for Spherical Harmonics
|
Header for a library for doing the Fast Transform for Spherical Harmonics. More...
#include <math.h>#include <stdlib.h>#include <stdio.h>#include <assert.h>#include <string.h>#include <time.h>#include "fftw.h"#include "rfftw.h"Go to the source code of this file.
Data Structures | |
| struct | Ftrigtw_Plan |
| Holder for precomputed FFTW objects. More... | |
| struct | Dense_Matrix |
| An ordinary (one dimensional) matrix. More... | |
| struct | Dense_Vector |
| An ordinary (one dimensional) vector. More... | |
| struct | Banded_Matrix |
| A one dimensional sparse matrix, with banded structure. More... | |
| struct | Bdmat_Op_Workspace |
| Workspace for Banded_Matrix routines. More... | |
| struct | Dyadic_Gsearch_Save |
| Workspace for "best non-decreasing dyadic partition" search. More... | |
| struct | Fast1_Save |
| Extra things to save for fast1 algorithm. More... | |
| struct | Local_Trig_Interval |
| Information to do a local trigonometric transform on an interval. More... | |
| struct | Pm_1D |
| Hold a compressed matrix of Associate Legendre functions of a fixed order. More... | |
| struct | Pm_Direct_bd |
| Hold a banded matrix of Associate Legendre functions of a fixed order. More... | |
| struct | Pm_Direct_d |
| Hold a dense matrix of Associate Legendre functions of a fixed order. More... | |
| struct | Pm_1D_Workspace |
| Hold workspace and a few precomputed values for the fast synthesis/analysis. More... | |
| struct | Pmncos_Recurrence_Save |
| Hold data and workspace to do the three-term recurrence for a vector of sample points. More... | |
Defines | |
| #define | PI 3.14159265358979323846264338328 |
| #define | USE_double 1 |
| #define | REAL double |
Functions | |
| Dense_Vector | init_dvect_memory (unsigned int n) |
| void | give_dvect_memory (Dense_Vector *current, Dense_Vector *previous) |
| Dense_Matrix | init_dmat_memory (unsigned int n) |
| void | give_dmat_memory (Dense_Matrix *current, Dense_Matrix *previous) |
| void | free_dmat_memory (Dense_Matrix *in) |
| void | dump_bin_dmat (Dense_Matrix *x, FILE *out) |
| void | load_bin_dmat (Dense_Matrix *x, FILE *in) |
| void | dmat_dvect_multiply (Dense_Vector *out, Dense_Matrix *inmat, Dense_Vector *invect) |
| void | dmat_t_dvect_multiply (Dense_Vector *out, Dense_Matrix *inmat, Dense_Vector *invect) |
| Banded_Matrix | init_bdmat_memory (int max_size, int max_rows, int max_bands) |
| void | give_bdmat_memory (Banded_Matrix *current, Banded_Matrix *previous) |
| void | free_bdmat_memory (Banded_Matrix *in) |
| void | bdmat_copy (Banded_Matrix *out, Banded_Matrix *in) |
| void | dump_bin_bdmat (Banded_Matrix *x, FILE *out) |
| void | load_bin_bdmat (Banded_Matrix *x, FILE *in) |
| void | bdmat_dvect_multiply (Dense_Vector *out, Banded_Matrix *inmat, Dense_Vector *invect) |
| void | bdmat_t_dvect_multiply (Dense_Vector *out, Banded_Matrix *inmat, Dense_Vector *invect) |
| void | dmat_to_bdmat (Banded_Matrix *out, Dense_Matrix *in, REAL cutoff, int min_gap) |
| int | dyadic_gsearch (Dyadic_Gsearch_Save *dy_gs_save) |
| void | dyadic_gsearch_init (Dyadic_Gsearch_Save *dy_gs_save, int num_levels) |
| void | dyadic_gsearch_free (Dyadic_Gsearch_Save *dy_gs_save) |
| void | fast1_fromfile (int *numpts_ptr, int *band_limit_ptr, REAL **node_ptr, REAL **weight_ptr, Pm_1D **pmn_matrix_ptr, Pm_1D_Workspace *pmnwork, FILE *fp) |
| void | load_fast1 (int *numpts_ptr, int *band_limit_ptr, int *num_levels_ptr, REAL **node_ptr, REAL **weight_ptr, Fast1_Save *saves_fordump, Pm_1D **pmn_matrix_ptr, FILE *fp) |
| void | direct1_fromfile (int *numpts_ptr, int *band_limit_ptr, REAL **node_ptr, REAL **weight_ptr, Pm_Direct_d **pmn_matrix_ptr, Pm_1D_Workspace *pmnwork, FILE *fp) |
| void | load_direct1 (int *numpts_ptr, int *band_limit_ptr, REAL **node_ptr, REAL **weight_ptr, Pm_Direct_d **pmn_matrix_ptr, FILE *fp) |
| void | dctw (REAL *fcn, Ftrigtw_Plan *main_plan, int dir) |
| void | dctw_init (Ftrigtw_Plan *main_plan, int flags, int numpts) |
| void | rfftw_to_NR_format (REAL *data_nr, REAL *data_rfftw, int numpts, int dir) |
| void | lctw (REAL *fcn, Ftrigtw_Plan *main_plan) |
| void | lctw_init (Ftrigtw_Plan *main_plan, int flags, int numpts) |
| REAL | dualabell (REAL(*origbell)(int, int), int laplength, int t) |
| void | bell_1size_init (REAL *bellout, REAL(*whichbell)(int, int), int lapleft, int center, int lapright, int dual_flag) |
| void | fold_e_e_1s (REAL *coef, REAL *fcn, int numpts, REAL *left, int n_left, REAL *right, int n_right, REAL *bell, int dir) |
| void | fold_e_o_1s (REAL *coef, REAL *fcn, int numpts, REAL *left, int n_left, REAL *right, int n_right, REAL *bell, int dir) |
| REAL | Pmncos (int order, int index, REAL phi) |
| void | Pmncos_resave_init (Pmncos_Recurrence_Save *pmn_save, REAL *node, int numpts) |
| void | next_rtsinPmncos (REAL *outfcn, Pmncos_Recurrence_Save *pmn_save, int halfpts, int order, int index) |
| void | Pmncos_resave_destroy (Pmncos_Recurrence_Save *pmn_save) |
| void | direct1_tofile (int numpts, int band_limit, REAL *node, REAL *weight, FILE *fp) |
| void | init_direct1 (Pm_Direct_d **out, int halfpts, int band_limit, REAL *node) |
| void | dump_direct1 (int numpts, int band_limit, REAL *node, REAL *weight, Pm_Direct_d *pmn_matrix, FILE *fp) |
| REAL | fast1_tofile (int numpts, int band_limit, REAL *node, REAL *weight, REAL epsilon, FILE *fp) |
| void | init_fast1 (Pm_1D **out, Fast1_Save *saves_fordump, int halfpts, int band_limit, REAL *node, int *numlevels, REAL epsilon, REAL(*bell_choice)(int, int)) |
| void | dump_fast1 (int numpts, int band_limit, int num_levels, REAL *node, REAL *weight, Fast1_Save *saves_fordump, Pm_1D *pmn_matrix, FILE *fp) |
| void | Pm_direct1_analyse (REAL *outcoef, Pm_Direct_d *inmat, REAL *infcn, Pm_1D_Workspace *pmnwork) |
| void | Pm_direct1_synthesize (REAL *outfcn, Pm_Direct_d *inmat, REAL *incoef, Pm_1D_Workspace *pmnwork) |
| REAL | bellmat1 (int laplength, int t) |
| REAL | bellmat2 (int laplength, int t) |
| REAL | bellmat3 (int laplength, int t) |
| REAL | bellmat4 (int laplength, int t) |
| REAL | bellmat5 (int laplength, int t) |
| REAL | bellmat6 (int laplength, int t) |
| REAL | bellmat7 (int laplength, int t) |
| REAL | bellmat8 (int laplength, int t) |
| REAL | bellmat9 (int laplength, int t) |
| REAL | bellmat10 (int laplength, int t) |
| REAL | bellmat11 (int laplength, int t) |
| REAL | bellmat12 (int laplength, int t) |
| REAL | bellmat13 (int laplength, int t) |
| REAL | bellmat14 (int laplength, int t) |
| REAL | bellmat15 (int laplength, int t) |
| REAL | bellmat16 (int laplength, int t) |
| REAL | bellmat17 (int laplength, int t) |
| REAL | bellmat18 (int laplength, int t) |
| REAL | bellmat19 (int laplength, int t) |
| REAL | bellmat20 (int laplength, int t) |
| void | Pm_1d_analyse (REAL *outcoef, Pm_1D *inmat, REAL *infcn, Pm_1D_Workspace *pmnwork) |
| void | Pm_1d_synthesize (REAL *outfcn, Pm_1D *inmat, REAL *incoef, Pm_1D_Workspace *pmnwork) |
| void | mk_gnode_gweight (REAL *gnode, REAL *gweight, REAL epsilon, int numpts) |
| void | mk_cosi_gnode (REAL *gnode, REAL epsilon, int numpts) |
| void | cosi_gnode_to_gweight (REAL *gweight, REAL *gnode, int numpts) |
| double | second () |
| char * | getoption (const char *flag, int argc, char **argv) |
| void | pointwise_multiply (REAL *out, REAL *in_1, REAL *in_2, int numpts) |
| void | reflect_evenodd (REAL *even, REAL *odd, REAL *whole, int numpts, int dir) |
| void | remove_rootsin (REAL *out, REAL *in, REAL *node, int numpts) |
| void | dyadic_g_ilist_init (Local_Trig_Interval *ilist[2], int *ints_used, int *coefs_used, REAL **bell_handle, int *bell_length, int **bell_offsets, int halfpts, int num_levels, REAL(*bell_choice)(int, int), int flags) |
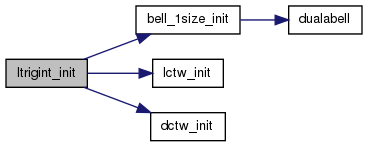
| void | ltrigint_init (Local_Trig_Interval *out, int numpts, int left_extra, int right_extra, int fcn_offset, int coef_offset, REAL(*bell_choice)(int, int), int which_transform, int fftw_flags) |
| void | gsearch_to_ilist (Local_Trig_Interval *ilist_out, int *intervals_kept, int max_intervals, Local_Trig_Interval *ilist_in, Dyadic_Gsearch_Save *dy_gs_save, int halfpts) |
| void | evaluate_intlist (REAL *outfcn, REAL *incoef, Local_Trig_Interval *interval_list, int num_intervals) |
| void | expand_d_intlist (REAL *outcoef, REAL *infcn, Local_Trig_Interval *interval_list, int num_intervals) |
| void | expand_intlist (REAL *outcoef, REAL *infcn, Local_Trig_Interval *interval_list, int num_intervals) |
| int | count_thresh (REAL *lambda, int howmany, REAL thresh) |
| void | init_Pm_1d_workspace (Pm_1D_Workspace *out, int numpts, int band_limit, REAL *node, REAL *weight) |
| void | ftgaqd (int *nlat, REAL *theta, REAL *wts, REAL *work, int *lwork, int *ierror) |
| void | gnode_to_Pmninit (REAL ***sofar, REAL **ex, REAL **why, int **size, REAL *gnode, int hemipts) |
Header for a library for doing the Fast Transform for Spherical Harmonics.
| #define REAL double |
REAL is the chosen floating-point data type (float or double)
| #define USE_double 1 |
USE_double sould be defined by a compiler flag
| void bdmat_copy | ( | Banded_Matrix * | out, |
| Banded_Matrix * | in | ||
| ) |
This routine copies a Banded_Matrix.
INPUTS: in -- the Banded_Matrix to copy
OUTPUT: out -- the values of in are copied to out Should be initialized as follows

| void bdmat_dvect_multiply | ( | Dense_Vector * | out, |
| Banded_Matrix * | inmat, | ||
| Dense_Vector * | invect | ||
| ) |
This routine applies a Banded_Matrix to a Dense_Vector to produce a Dense_Vector. The matrix may be square or rectangular.
INPUTS:
OUTPUT: out is modified so out = inmat * invect
NOTES:

| void bdmat_t_dvect_multiply | ( | Dense_Vector * | out, |
| Banded_Matrix * | inmat, | ||
| Dense_Vector * | invect | ||
| ) |
This routine applies the TRANSPOSE of a Banded_Matrix to a Dense_Vector to produce a Dense_Vector. The matrix may be square or rectangular.
INPUTS:
OUTPUT: out is modified so out = TRANSPOSE(inmat) * invect
NOTES:

| void bell_1size_init | ( | REAL * | bellout, |
| REAL(*)(int, int) | whichbell, | ||
| int | lapleft, | ||
| int | center, | ||
| int | lapright, | ||
| int | dual_flag | ||
| ) |
Computes bell values for a given size and overlap configuration.
INPUTS:
OUTPUT: bellout --is written onto. The first lapleft+center+lapright entries are used.
Generally, the bell will look like
---------------------\
_____/ -\______
_________/---- - ___
___/--- \-
/-- \
|---------------|--------------|--------------------|--------|--------|
lapleft | lapleft lapright|lapright
|- - - - - - - - - center - - - - - - - - - -| NOTES:


| void cosi_gnode_to_gweight | ( | REAL * | gweight, |
| REAL * | gnode, | ||
| int | numpts | ||
| ) |
This routine computes the gaussian weights that go with a set of gaussian nodes.
The nodes input here are \(\cos^{-1}(\text{the usual nodes} )\).
INPUTS:
OUTPUTS: numpts values of gweight are filled in
NOTES:

| int count_thresh | ( | REAL * | lambda, |
| int | howmany, | ||
| REAL | thresh | ||
| ) |
This function counts how many members of lambda are above thresh in absolute value.
INPUTS:
OUTPUT: -- returns the count
| void dctw | ( | REAL * | fcn, |
| Ftrigtw_Plan * | main_plan, | ||
| int | dir | ||
| ) |
Computes the disrete cosine transform of fcn and puts the coefficients back into fcn
This is the DCT at half integer points.
INPUTS:
OUTPUT: fcn.
numpts-1 k (j+0.5)
fcn[k]= SUM fcn[j] cos( PI ---------------- ) *norm
j=0 numpts
set for L^2 normalization.
NOTES:

| void dctw_init | ( | Ftrigtw_Plan * | main_plan, |
| int | flags, | ||
| int | numpts | ||
| ) |
This routine initializes for dctw
We initialize trigonometic things used by the lct and dct portions, and call the initailizer for the fftw real transform (forward). INPUTS: - main_plan -- a structure that will hold the things we generate Memory for its fields is allocated in this routine. - flags -- flags passed directly to the rfftw initializer - numpts -- the number of points on which we will transform MUST be even OUTPUTS: main_plan is filled in: NOTES: - comment better
keep these always as double so we don't lose precision

| void direct1_fromfile | ( | int * | numpts_ptr, |
| int * | band_limit_ptr, | ||
| REAL ** | node_ptr, | ||
| REAL ** | weight_ptr, | ||
| Pm_Direct_d ** | pmn_matrix_ptr, | ||
| Pm_1D_Workspace * | pmnwork, | ||
| FILE * | fp | ||
| ) |
This routine loads the initialization dumped by dump_direct1, interprets it and does all the set-up necessary to do the synthesis or analysis transform.
INPUTS: fp -- the objects are read from the file pointed to by fp, in binary format. The file must be opened before calling this routine.
OUTPUTS:
NOTES:
| void direct1_tofile | ( | int | numpts, |
| int | band_limit, | ||
| REAL * | node, | ||
| REAL * | weight, | ||
| FILE * | fp | ||
| ) |
This routine initializes the direct transform for spherical harmonics (version 1) and dumps it to a file.
INPUTS:
OUTPUTS: fp - the objects created are written onto the file pointed to by fp, in binary format. The file must be opened before calling this routine.
NOTES:
| void dmat_dvect_multiply | ( | Dense_Vector * | out, |
| Dense_Matrix * | inmat, | ||
| Dense_Vector * | invect | ||
| ) |
Apply a matrix to a vector to get a new vector. The matrix is in Dense_Matrix format, and the vectors in Dense_Vector format.
INPUTS:
OUTPUT: out -- inmat * invect = out
NOTES:

| void dmat_t_dvect_multiply | ( | Dense_Vector * | out, |
| Dense_Matrix * | inmat, | ||
| Dense_Vector * | invect | ||
| ) |
Apply the TRANSPOSE of a matrix to a vector to get a new vector. The matrix is in Dense_Matrix format, and the vectors in Dense_Vector format.
INPUTS:
OUTPUT: out -- TRANSPOSE(inmat) * invect = out
NOTES:

| void dmat_to_bdmat | ( | Banded_Matrix * | out, |
| Dense_Matrix * | in, | ||
| REAL | cutoff, | ||
| int | min_gap | ||
| ) |
Convert a matrix in Dense_Matrix form to Banded_Matrix form.
INPUT:
OUTPUT: out
NOTES:

Return the value of the dual to the given bell.
INPUTS:
OUTPUT: return the REAL value at that point.

| void dump_bin_bdmat | ( | Banded_Matrix * | x, |
| FILE * | out | ||
| ) |
This routine dumps a Banded_Matrix to a file in binary format.
INPUTS:
OUTPUT: writes into the file given by out. The writing mode ("wb" or "ab") is determined outside of this routine.

| void dump_bin_dmat | ( | Dense_Matrix * | x, |
| FILE * | out | ||
| ) |
This routine dumps a Dense_Matrix to a file in binary format.
This is efficient, but not human readable.
INPUTS:
OUTPUT: writes into the file given by out. The writing mode ("wb" or "ab") is determined outside of this routine.

| void dump_direct1 | ( | int | numpts, |
| int | band_limit, | ||
| REAL * | node, | ||
| REAL * | weight, | ||
| Pm_Direct_d * | pmn_matrix, | ||
| FILE * | fp | ||
| ) |
This routine dumps the initialization constructed by init_direct1 and general parameters for the direct transform for spherical harmonics, dense version.
INPUTS:
OUTPUTS: fp -- the objects above are written into the file pointed to by fp, in binary format. The file must be opened before calling this routine.


| void dump_fast1 | ( | int | numpts, |
| int | band_limit, | ||
| int | num_levels, | ||
| REAL * | node, | ||
| REAL * | weight, | ||
| Fast1_Save * | saves_fordump, | ||
| Pm_1D * | pmn_matrix, | ||
| FILE * | fp | ||
| ) |
This routine dumps the initialization constructed by init_fast1 and general parameters for the fast transform for spherical harmonics, version 1.
INPUTS:
OUTPUTS: fp -- the objects above are written into the file pointed to by fp, in binary format. The file must be opened before calling this routine.


| void dyadic_g_ilist_init | ( | Local_Trig_Interval * | ilist[2], |
| int * | ints_used, | ||
| int * | coefs_used, | ||
| REAL ** | bell_handle, | ||
| int * | bell_length, | ||
| int ** | bell_offsets, | ||
| int | halfpts, | ||
| int | num_levels, | ||
| REAL(*)(int, int) | bell_choice, | ||
| int | flags | ||
| ) |
This routine constructs the interval list for a dyadic partition suitable for the growing interval size search (gsearch).
INPUTS:
OUTPUTs:
NOTES:
set which_transform

| int dyadic_gsearch | ( | Dyadic_Gsearch_Save * | dy_gs_save | ) |
This routine implements a `best non-decreasing dyadic partition' search. It finds the partition with lowest cost under the restriction that an interval's right neighbor is either the same size or one size (2x) larger. Generally this is to be used with local cosine. When an interval's left neighbor is the same size, we use a regular full sized bell and put the cost of this expansion in .cost_full[][]. When the left neighbor is smaller we shrink the left edge of the bell, making it asymmetric and yielding .cost_asym[][].
The search tree is grown from the left, with an interval having children its allowed right neighbors. The cost of a partition is the cost of a path from the left edge to the right edge. Since each interval has two costs, the path into an interval is also important.
| _--------------O | |/ | /| _-----O-------|--------->O | O-|-/ _--|--------/ | \| | / | | | |~--O---|-->O----|--->O----|---->O |
The generic decision step is: assume the current node's children contain the minimal cost of a path from them to the right. Compare these costs and ADD the smaller to the full and asym costs of the current node. We process intervals in order of the x-coordinate of their center, starting at the right.
INPUTS: dy_gs_save -- a structure holding memory for the costs, branching and ordering of interval. See the declaration of the structure Dyadic_Gsearch_Save for the full description of its fields.
OUTPUTS: returns the minimal cost, and also stores it in dy_gs_save.costfull[dy_gs_save.best_level][0]. To determine the partition chosen, start at [best_level][0] and follow .branching[][], which has values one of {RIGHTEDGE=0, SAMESIZE=1, UPSIZE=2}
| void dyadic_gsearch_free | ( | Dyadic_Gsearch_Save * | dy_gs_save | ) |
This function frees the structure Dyadic_Gsearch_Save used by dyadic_gsearch and initialized by dyadic_gsearch_init.
INPUTS: dy_gs_save -- a pointer to the structure to free
OUTPUT: none

| void dyadic_gsearch_init | ( | Dyadic_Gsearch_Save * | dy_gs_save, |
| int | num_levels | ||
| ) |
This function initializes the structure Dyadic_Gsearch_Save for use by dyadic_gsearch. Memory can be freed by dyadic_gsearch_free.
INPUTS:
OUTPUT: dy_gs_save -- memory is allocated and some things filled in.

| void evaluate_intlist | ( | REAL * | outfcn, |
| REAL * | incoef, | ||
| Local_Trig_Interval * | interval_list, | ||
| int | num_intervals | ||
| ) |
This routine does a LCT/DCT evaluation based on a list of intervals.
INPUTS:
OUTPUTS: outfcn is filled in. incoef is destroyed
NOTES:

| void expand_d_intlist | ( | REAL * | outcoef, |
| REAL * | infcn, | ||
| Local_Trig_Interval * | interval_list, | ||
| int | num_intervals | ||
| ) |
This routine does a LCT/DCT expansion on a list of intervals.
This version expands using the DUAL bell. Otherwise it is just like expand_intlist.
See expand_intlist for a full description.

| void expand_intlist | ( | REAL * | outcoef, |
| REAL * | infcn, | ||
| Local_Trig_Interval * | interval_list, | ||
| int | num_intervals | ||
| ) |
This routine does a LCT/DCT expansion on a list of intervals.
INPUTS:
OUTPUTS: outcoef is filled in. infcn is untouched
| void fast1_fromfile | ( | int * | numpts_ptr, |
| int * | band_limit_ptr, | ||
| REAL ** | node_ptr, | ||
| REAL ** | weight_ptr, | ||
| Pm_1D ** | pmn_matrix_ptr, | ||
| Pm_1D_Workspace * | pmnwork, | ||
| FILE * | fp | ||
| ) |
This routine loads the initialization dumped by dump_fast1, interprets it and does all the set-up necessary to do the synthesis or analysis transform
INPUTS: fp -- the objects are read from the file pointed to by fp, in binary format. The file must be opened before calling this routine.
OUTPUTS:
NOTES:
| REAL fast1_tofile | ( | int | numpts, |
| int | band_limit, | ||
| REAL * | node, | ||
| REAL * | weight, | ||
| REAL | epsilon, | ||
| FILE * | fp | ||
| ) |
This routine initializes the fast transform for spherical harmonics (version 1) and dumps it to a file. This version is designed for the novice user, and so doesn't allow tuning.
INPUTS:
OUTPUTS:
NOTES:
| void fold_e_e_1s | ( | REAL * | coef, |
| REAL * | fcn, | ||
| int | numpts, | ||
| REAL * | left, | ||
| int | n_left, | ||
| REAL * | right, | ||
| int | n_right, | ||
| REAL * | bell, | ||
| int | dir | ||
| ) |
Computes the folded version of a function, which is then usually DCTed also can unfold
INPUTS:
OUTPUT:
NOTES:
| void fold_e_o_1s | ( | REAL * | coef, |
| REAL * | fcn, | ||
| int | numpts, | ||
| REAL * | left, | ||
| int | n_left, | ||
| REAL * | right, | ||
| int | n_right, | ||
| REAL * | bell, | ||
| int | dir | ||
| ) |
Computes the folded version of a function, which is then usually LCTed also can unfold.
INPUTS:
OUTPUT:
NOTES:
| void free_bdmat_memory | ( | Banded_Matrix * | in | ) |
This routine frees the memory that was given to a Banded_Matrix by init_bdmat_memory.
INPUT: in -- the Banded_Matrix to free. it must have been initialized by init_bdmat_memory, or we will attempt to free things not gotten by calloc, probaby causing catastrophic failure.
NOTES:

| void free_dmat_memory | ( | Dense_Matrix * | in | ) |
This routine frees the memory that was given to a Dense_Matrix by init_dmat_memory.
INPUT: in -- the Dense_Matrix to free. it must have been initialized by init_dmat_memory, or we will attempt to free things not gotten by calloc, probaby causing catastrophic failure.
NOTES:

This routine emulates gadq in the SPHEREPACK library
INPUTS:
OUTPUTS:
NOTES:

| char* getoption | ( | const char * | flag, |
| int | argc, | ||
| char ** | argv | ||
| ) |
This routine allows command line options, usually of the form: program -d 256. Normal usage in the program is:
if(getoption("-d",argc,argv)!=NULL)
degree=atoi(getoption("-d",argc,argv));The first call makes sure the option flag was indeed used. If it was, we call again to get the value as a string, then convert it using ato_ .
| void give_bdmat_memory | ( | Banded_Matrix * | current, |
| Banded_Matrix * | previous | ||
| ) |
This routine sets up memory for the next Banded_Matrix we wish to use.
It looks at the previous Banded_Matrix we used, and increments fields
INPUT: previous -- the last Banded_Matrix we used
OUTPUT: current -- the Banded_Matrix we wish to use next
We set the .band_p, .band_list, and .matrix fields to the next available ints and REAL. .max_size, .max_rows, and .max_bands are set to account for the amount used in previous. also set: .non_zero=0; .n_row=-1 .n_col=0

| void give_dmat_memory | ( | Dense_Matrix * | current, |
| Dense_Matrix * | previous | ||
| ) |
This routine sets up memory for the next Dense_Matrix we wish to use.
It looks at the previous Dense_Matrix we used, and increments fields
INPUT: previous -- the last Dense_Matrix we used.
OUTPUT: current -- the Dense_Matrix we wish to use next. We align current->matrix to the first space not used by previous->matrix, and set current->max_size to account for the amount used in previous.
| void give_dvect_memory | ( | Dense_Vector * | current, |
| Dense_Vector * | previous | ||
| ) |
This routine sets up memory for the next Dense_Vector we wish to use. It looks at the previous Dense_Vector we used, and increments fields
INPUT: previous -- the last Dense_Vector we used
OUTPUT: current -- the Dense_Vector we wish to use next We align current->vector to the first space not used by previous->vector, and set current->max_size to account for the amount used in previous.

| void gnode_to_Pmninit | ( | REAL *** | sofar, |
| REAL ** | ex, | ||
| REAL ** | why, | ||
| int ** | size, | ||
| REAL * | gnode, | ||
| int | hemipts | ||
| ) |
Converts gnodes to the initialization needed for next_rtsinPmncos.
Takes the place of the initialization step in next_rtsinPmncos(....,-1)
INPUTS:
OUTPUTS : This function creates the arrays above:
| void gsearch_to_ilist | ( | Local_Trig_Interval * | ilist_out, |
| int * | intervals_kept, | ||
| int | max_intervals, | ||
| Local_Trig_Interval * | ilist_in, | ||
| Dyadic_Gsearch_Save * | dy_gs_save, | ||
| int | halfpts | ||
| ) |
This function converts the choices made by the dyadic_gsearch to a list of intervals.
INPUTS:
OUTPUT:
NOTES:
| Banded_Matrix init_bdmat_memory | ( | int | max_size, |
| int | max_rows, | ||
| int | max_bands | ||
| ) |
This routine gets a large amount of memory for Banded_Matrix's, and gives it to a single Banded_Matrix to hold. This special Banded_Matrix acts as a pointer to this block of memory, and also keeps track of how large this memory is.
INPUT:
OUPUT: returns a Banded_Matrix with
| void init_direct1 | ( | Pm_Direct_d ** | out, |
| int | halfpts, | ||
| int | band_limit, | ||
| REAL * | node | ||
| ) |
This routine initializes for the transform for spherical harmonics, direct version 1. This version simple precomputes the Pm matrices and stores them in dense matrix format.
INPUTS:
OUTPUTS: out -- memory is allocated for band_limit (==order_limit) Pm_Direct_d structures, each representing the matrix for one m. Various bits of memory are allocated for these, and values filled in.

| Dense_Matrix init_dmat_memory | ( | unsigned int | n | ) |
This routine gets a large amount of memory for Dense_Matrix's, and gives it to a single Dense_Matrix to hold. This special Dense_Matrix acts as a pointer to this block of memory, and also keeps track of how large this memory is.
INPUT: n -- the amount of memory to get
OUPUT: returns a Dense_Matrix with
| Dense_Vector init_dvect_memory | ( | unsigned int | n | ) |
This routine gets a large amount of memory for Dense_Vector's, and gives it to a single Dense_Vector to hold. This special Dense_Vector acts as a pointer to this block of memory, and also keeps track of how large this memory is.
INPUT: n -- the amount of memory to get
OUPUT: returns a Dense_Vector with

| void init_fast1 | ( | Pm_1D ** | out, |
| Fast1_Save * | saves_fordump, | ||
| int | halfpts, | ||
| int | band_limit, | ||
| REAL * | node, | ||
| int * | numlevels, | ||
| REAL | epsilon, | ||
| REAL(*)(int, int) | bell_choice | ||
| ) |
This routine initializes for the fast transform for spherical harmonic, version 1.
Version 1 compresses in 1D (each Pmn separately) and chooses a single partition for each m and parity. By choosing a single partition we minimize the trig transform cost, but sacrifice precision. This is appropriate for small problems, near the break-even point, since it reduces overhead.
INPUTS:
OUTPUTS:
NOTES:

| void init_Pm_1d_workspace | ( | Pm_1D_Workspace * | out, |
| int | numpts, | ||
| int | band_limit, | ||
| REAL * | node, | ||
| REAL * | weight | ||
| ) |
This routine initializes a structure Pmncos_1D_Workspace, which is used to hold workspace and a few precomputed values for use in the synthesis/analysis routines.
INPUTS:
OUTPUT: out -- memory is allocated for the fields of out, and some values are precomputed.
NOTE:
| void lctw | ( | REAL * | fcn, |
| Ftrigtw_Plan * | main_plan | ||
| ) |
Computes the local cosine transform of fcn and puts the coeficients back into fcn.
The local cosine transform is also known as the type 4 discrete cosine transform.
This is the LCT at half integer points. Is its own inverse.
INPUTS:
OUTPUT: fcn. Puts the coefficients in fcn. specifically: \[ f(k) =norm \sum_{j=0}^{numpts-1} f(j) \cos\left(\pi\frac{(k+1/2)(j+1/2)}{numpts}\right) \]
numpts-1 (k+0.5) (j+0.5)
fcn[k]= SUM fcn[j] cos( PI ---------------- ) *norm
j=0 numpts
set for \(L^2\) normalization.
NOTES:
| void lctw_init | ( | Ftrigtw_Plan * | main_plan, |
| int | flags, | ||
| int | numpts | ||
| ) |
This routine initializes for lctw
We initialize trigonometic things used by the lct and dct portions, and call the initailizer for the fftw real transform (forward).
INPUTS:
OUTPUTS: main_plan is filled in:
NOTES:

| void load_bin_bdmat | ( | Banded_Matrix * | x, |
| FILE * | in | ||
| ) |
This routine boads a Banded_Matrix to a file in binary format, as written by dump_bin_bdmat
INPUTS:
OUTPUT: x -- is filled in.

| void load_bin_dmat | ( | Dense_Matrix * | x, |
| FILE * | in | ||
| ) |
This routine loads a Dense_Matrix from a file in binary format, as written by dump_bin_dmat.
INPUTS:
OUTPUT: x -- is filled in.

| void load_direct1 | ( | int * | numpts_ptr, |
| int * | band_limit_ptr, | ||
| REAL ** | node_ptr, | ||
| REAL ** | weight_ptr, | ||
| Pm_Direct_d ** | pmn_matrix_ptr, | ||
| FILE * | fp | ||
| ) |
This routine loads the initialization dumped by dump_direct1 We interpret what we read and re-align pointers and such to get things ready to use
INPUTS: fp -- the objects are read from the file pointed to by fp, in binary format. The file must be opened before calling this routine.
OUTPUTS:

| void load_fast1 | ( | int * | numpts_ptr, |
| int * | band_limit_ptr, | ||
| int * | num_levels_ptr, | ||
| REAL ** | node_ptr, | ||
| REAL ** | weight_ptr, | ||
| Fast1_Save * | saves_fordump, | ||
| Pm_1D ** | pmn_matrix_ptr, | ||
| FILE * | fp | ||
| ) |
This routine loads the initialization dumped by dump_fast1.
We interpret what we read and re-align pointers and such to get things ready to use.
INPUTS: fp -- the objects are read from the file pointed to by fp, in binary format. The file must be opened before calling this routine
OUTPUTS:
NOTES:

| void ltrigint_init | ( | Local_Trig_Interval * | out, |
| int | numpts, | ||
| int | left_extra, | ||
| int | right_extra, | ||
| int | fcn_offset, | ||
| int | coef_offset, | ||
| REAL(*)(int, int) | bell_choice, | ||
| int | which_transform, | ||
| int | fftw_flags | ||
| ) |
This routine initializes a Local_Trig_Interval.
INPUTS:
OUTPUTS: out -- is written onto with the above info.
NOTES:

| void mk_gnode_gweight | ( | REAL * | gnode, |
| REAL * | gweight, | ||
| REAL | epsilon, | ||
| int | numpts | ||
| ) |
This routine constructs the gaussian nodes and weights.
We make cosine inverse of the ordinary gaussian nodes.
INPUTS:
OUTPUTS:


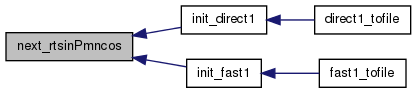
| void next_rtsinPmncos | ( | REAL * | outfcn, |
| Pmncos_Recurrence_Save * | pmn_save, | ||
| int | halfpts, | ||
| int | order, | ||
| int | index | ||
| ) |
Do one step in the recurrence process then output the results.
This saves on memory if we are trying to compress all associated Legendre fcns of some order. This version is super stabilized for all conditions.
INPUTS:
OUTPUTS : results are output in outfcn, above
USAGE: You must call this function for successive values of index, starting at 0. Order must remain fixed.
NOTES:
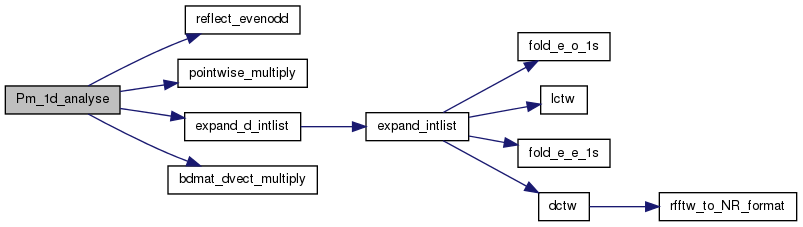
| void Pm_1d_analyse | ( | REAL * | outcoef, |
| Pm_1D * | inmat, | ||
| REAL * | infcn, | ||
| Pm_1D_Workspace * | pmnwork | ||
| ) |
Expands (analyses) a function into spherical harmonic coefficients.
This routine only does one order (m) so it is really only an Associaded Legendre Function analyser.
INPUTS:
OUTPUTS: outcoef -- an array of the coefficients computed. The information on how many of these to compute is encoded by the number of rows in inmat.
NOTES:
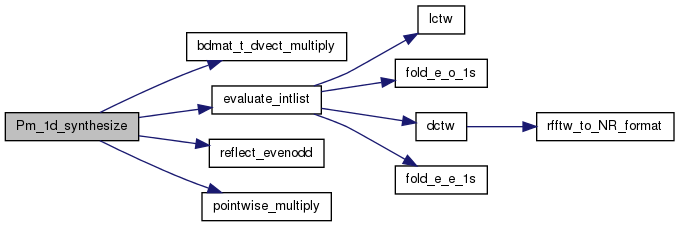
| void Pm_1d_synthesize | ( | REAL * | outfcn, |
| Pm_1D * | inmat, | ||
| REAL * | incoef, | ||
| Pm_1D_Workspace * | pmnwork | ||
| ) |
Evaluates (synthesizes) a function from spherical harmonic coefficients.
This routine only does one order (m) so it is really only an Associaded Legendre Function synthesizer.
INPUTS:
OUTPUTS: outfcn -- an array of REALs to hold the computed function. Its length is encoded in the number of columns in inmat.
NOTES:
| void Pm_direct1_analyse | ( | REAL * | outcoef, |
| Pm_Direct_d * | inmat, | ||
| REAL * | infcn, | ||
| Pm_1D_Workspace * | pmnwork | ||
| ) |
Expand (analyses) a function into spherical harmonic coefficients.
This routine only does one order (m) so it is really only an Associated Legendre Function analyser.
INPUTS:
OUTPUTS: outcoef -- an array of the coefficients computed. The information on how many of these to compute is encoded by the number of rows in inmat.
NOTES:
| void Pm_direct1_synthesize | ( | REAL * | outfcn, |
| Pm_Direct_d * | inmat, | ||
| REAL * | incoef, | ||
| Pm_1D_Workspace * | pmnwork | ||
| ) |
Evaluates (synthesizes) a function from spherical harmonic coefficients.
This routine only does one order (m) so it is really only an Associaded Legendre Function synthesizer.
INPUTS:
OUTPUTS: outfcn -- an array of REALs to hold the computed function. Its length is encoded in the number of columns in inmat
NOTES:
Evaluate an associated Legendre function P^m_n at any point.
This routine is super stabilized for all conditions.
INPUTS:
OUTPUTS: returns \(cP^m_n(\cos(\phi))\) with c to make L^2 normalized.
m
P (cos(phi)) * const
nThe constant is set so we are L^2 normalized. Since the number of points to be used is not known, we cannot adjust for the discretization.
NOTES:
| void Pmncos_resave_destroy | ( | Pmncos_Recurrence_Save * | pmn_save | ) |
destroy (free) a structure Pmncos_Recurrence_Save
INPUTS: pmn_save -- the structure to free
OUTPUTS : The memory held by pmn_save is freed
| void Pmncos_resave_init | ( | Pmncos_Recurrence_Save * | pmn_save, |
| REAL * | node, | ||
| int | numpts | ||
| ) |
Converts a set of nodes (often gaussian) to the initialization needed for the associated legendre function recurrence.
INPUTS:
OUTPUTS : This function creates memory for the arrays in pmn_save and initializes some values.
| void pointwise_multiply | ( | REAL * | out, |
| REAL * | in_1, | ||
| REAL * | in_2, | ||
| int | numpts | ||
| ) |
Pointwise multiply two vectors to form the third.
INPUTS:
OUTPUTS: out -- is written onto; out[i]=in_1[i]*in_2[i];
| void reflect_evenodd | ( | REAL * | even, |
| REAL * | odd, | ||
| REAL * | whole, | ||
| int | numpts, | ||
| int | dir | ||
| ) |
Form the even and odd parts of the input vector.
It can also reverse the process.
INPUTS:
OUTPUTS:
In forward mode even and out are written onto, with the even/odd reflections of whole:
If the number of points is odd, the center point is copied into even, and omitted from odd.
NOTES:
| void remove_rootsin | ( | REAL * | out, |
| REAL * | in, | ||
| REAL * | node, | ||
| int | numpts | ||
| ) |
Divide the vector in by sqrt(sin( node values)).
INPUTS:
OUTPUTS : out -- is written onto out[i]=in[i]/sqrt(sin(node[i]))
NOTES:

| void rfftw_to_NR_format | ( | REAL * | data_nr, |
| REAL * | data_rfftw, | ||
| int | numpts, | ||
| int | dir | ||
| ) |
Translates between the formats for the real discrete fourier transform used by the rfftw package and the Numerical Recipies routines. This helps allow the NR DCT routine to call the rfftw.
INPUTS:
OUTPUTS:
NOTES:

| double second | ( | ) |
return the current time for performance timings
 1.8.0
1.8.0

